Three problems with GitOps as deployment history, and how we overcome them

Laszlo Fogas

An often mentioned property of gitops is that it gives you a deployment history by nature.
As you keep updating your desired deployment state in git, it builds up to a trail of changes that you can use to tell what version was deployed at a given time.
Our finding is that this git history is too sparse and noisy at the same time to be used for anything practical without tooling.
In this blog post we describe three problems we experienced once we adopted gitops and Flux CD, and what measures we implemented in Gimlet to overcome them. You may face similar issues in your own gitops platform implementation and this blog post can give you ideas about how to solve them.
Let's dive into problem one, shall we?
Problem one: gitops is a technical history and it is not what developers care about
Developers want to know if their code is deployed. But all gitops tells them is how the image tag changed from one hash to another. Not very helpful.

When gitops promised an auditlog, we all dreamed of a future where we know what code was deployed and by whom at any given time. But all we have is a stream of yaml changes, that does not know much about the code version that was delivered.
It captures Kubernetes specific changes well, like a change in required CPU or an environment variable, but it does not know much about code version. The information what developers want to know the most about.
Ideally, as developers, we want to know the
- the reference to the commit or pull request that was merged and deployed
- the name of the PR or message of the deployed commit
- who was the creator of the commit
- and who deployed it.
With any possible additonal meta information that may help us in resolving an incident.
As 70% percent of issues are introduced with code changes as per the Google SRE book, knowing the largest possible context for each change could be material to our MTTR - or mean time to repair.
But the gitops history is not able to tell us any of this.
Unable to tell what was deployed, and often unable to even tell who started the deploy, as most gitops changes are made by bot accounts. This is not an auditlog.
But we can make it one.
Storing context information with gitops commits
To make gitops commits a real deployment history, at Gimlet, we store additional meta information with each commit. Besides the yaml changes, we store a release.json file with each gitops commit our tooling makes.
This file is ignored by Flux CD, so it does not interfere with the Kubernetes deployment, but contains the necessairy information to quickly reconstruct a deployment history out of gitops commits.
The key here is quickly. This is a denormalized form of metadata that otherwise could only be obtained through the references in the deployed manifest.
The release.json file is the serialized form of the Golang Release struct of the github.com/gimlet-io/gimlet-cli/pkg/dx package.
type Release struct {
App string
Env string
ArtifactID string
TriggeredBy string
Version *Version
GitopsRef string
GitopsRepo string
Created int64
RolledBack bool
}
type Version struct {
RepositoryName string
SHA string
Created int64
Branch string
Event GitEvent
SourceBranch string
TargetBranch string
Tag string
AuthorName string
AuthorEmail string
CommitterName string
CommitterEmail string
Message string
URL string
}
With this information available for every gitops commit, we can display the right context for each commit in Gimlet, and you can do it too in your own platform if you decide to build one.
Gimlet is a gitops based internal developer platform, and probably the fastest way to get a gitops platform on top of Flux and Kubernetes. With the release meta information stored in the gitops repository, getting the deployment history with the gimlet command line tool is reduced to the following command:
$ gimlet release list --env staging --app demo-app --limit 1
demo-app -> staging @0342ccba7fe85c35154d96e396589feeda803b7d (3 hours ago)
d4f3846f - Major change (4 hours ago) by Laszlo Fogas
gimlet-io/demo-app@main https://github.com/gimlet-io/demo-app/commit/d4f3846f2391215e529ed57b59621723619ba625
and similarly on the Gimlet Dashboard:
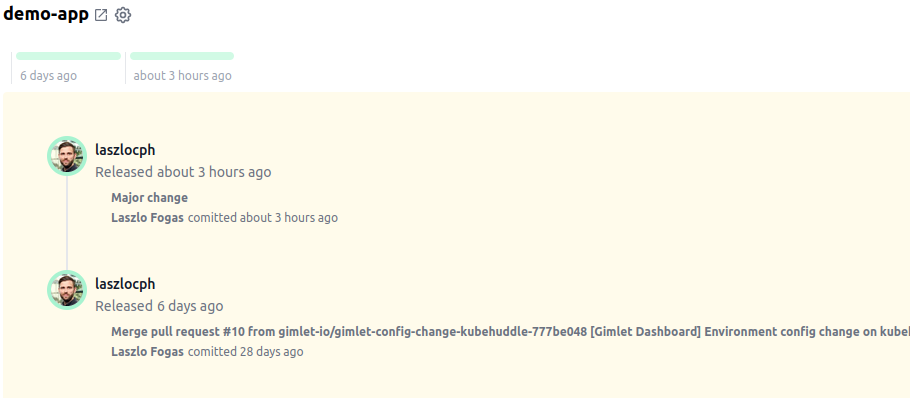
Now that we have a proper deployment history, let's address the next problem.
Problem two: gitops history is not a straight line
As a developer, you typically work with one service. But in the gitops repository we often store manifests for many services, thus looking at the git history of one service is not a straight line of git commits, but a rather sparse line.
The approach to reconstruct the deployment history for a single service depends on the folder strategy you use in the gitops repository.
Since the gitops repository structure is not prescribed by gitops, you can end up with a rather difficult task. This is a factor to consider when you design your gitops folder strategy, and it affects greatly your ability to construct the gitops history for a single service.
At Gimlet, we use folders to separate services from one another. With manifests stored under a specific path, getting the gitops history of one service is rather easy with the git command line tool: the git log -- path/to/service command returns the git commit history of the specified folder
But if you use Kustomize overlays to render the service manifests, constructing the history of a single service can become much more difficult as you need to factor in changes in base layers as well. And base layers are scattered in multiple folders, so getting the release history of a service becomes a rather complex task.
Problem three: traversing the git history is slow
Even though our approach makes the problem solvable with a git one-liner, we implement our tooling in Golang. Unfortunately, the de-facto git library, go-git is far from great at the task.
To get the history of a path, it traverses the git commit tree and checks the changed files in each commit to see if they are on the path where our service is. And it does it at a rather slow pace, orders of magnitude slower than the git binary.
With this issue, we arrived at problem three: speed.
Git was made for a specific usecase and depending the language library you use, speed can be an issue. The git binary that you use on the terminal is very well optimized code, and chances are that the library available for your language will be much slower. So the tooling you build is going to be much slower in constructing specific git histories.
Answering questions like:
- What was the last ten versions deployed from this service?
- What changes were made on production last Monday?
- What was the last ten deploys by Alice?
- What was the last ten deploys from repository X?
from hundreds, or thousands of commits made every week, may pose performance issues for your tooling.
Closing up
You may wonder that with the issues listed with gitops, is it really an approach to follow?
Our answer is yes.
Git is not a database but we try to use it as one, so certain usecase are hard. That's why we say at Gimlet that gitops heavily benefits from a platform. We would not use it without proper tooling.
But we like the incremental nature of gitops. As each change is a commit of text files, it makes debugging issues a lot easier. Having the possibility to look at the gitops repository at any moment, gives a level of transparency that is not matched by any other deployment approach we tried.
Onwards!
ps.: we love gitops, but we know it is not without problems. Here is another issue where we think gitops can use some platform love: How Flux broke the CI/CD feedback loop, and how we pieced it back together



