The cluster admin struggle, and ways to keep Kubernetes Resource Requests and Limits in check

Laszlo Fogas

There are only a few things to know about requests and limits, really.
- That it has odd units.
[...] memory are measured in bytes. You can express memory as a plain integer or as a fixed-point integer using one of these suffixes: E, P, T, G, M, K. You can also use the power-of-two equivalents: Ei, Pi, Ti, Gi, Mi, Ki. For example, the following represent roughly the same value:
128974848, 129e6, 129M, 123Mi
[1]
The expression 0.1 is equivalent to the expression 100m, which can be read as "one hundred millicpu". Some people say "one hundred millicores", and this is understood to mean the same thing.
[1]
That 1000CPU shares or
mis 1 CPU core.That cores are not dedicated.
That reaching CPU limit throttles.
That reaching memory limit kills the workload.
That you are either wasting money or harming the cluster.
If your usage is much lower than your request, you are wasting money. If it is higher, you are risking performance issues in the node.
[2]
- That you are on your own.
The enforcement of these limits are on the user, as there is no automatic mechanism to tell Kubernetes how much overcommit to allow.
[2]
Irony aside, you know this, and a bunch of devs too
still, the first approach to keep requests and limits in check in your cluster is education.
Training programs establish a good baseline in your team, internal wikis are there to look up best practices when needed, good infographics circulate social media to reinforce the learning.
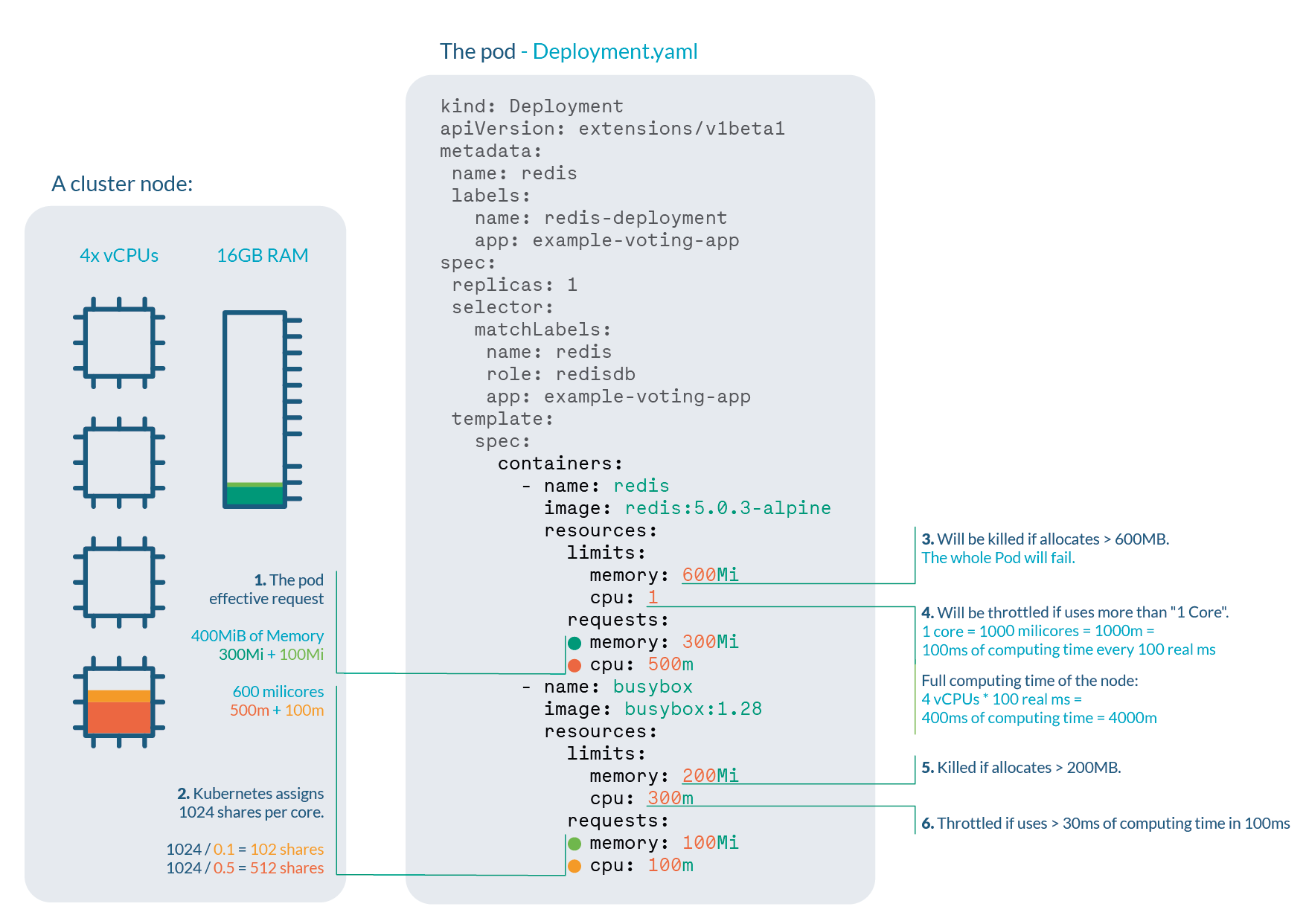 [2]
[2]
You will succeed eventually, knowledge will be evenly distributed in your team, but it's a long way.
Enforce some policies in the meantime to prevent the extremes
Kubernetes has two ways to prevent workloads from harming each other: LimitRange and ResourceQuota.
LimitRange keeps workloads in a healthy range - see min and max, also provides defaults - see default*, to applications that failed to set resource requirements.
apiVersion: v1
kind: LimitRange
metadata:
name: resource-limits
spec:
limits:
- type: Container
max:
cpu: '4'
memory: '8Gi'
min:
cpu: '100m'
memory: '50Mi'
default:
cpu: '300m'
memory: '200Mi'
defaultRequest:
cpu: '200m'
memory: '200Mi'
maxLimitRequestRatio:
cpu: '10'
memory: '1'
It also helps you enforce your cluster over-commit policies via maxLimitRequestRatio.
The above sample allows a lax 10x CPU overcommit, which could still be healthy if services are not bursting at the same time, but it's very strict about memory. Understandably, as reaching the CPU limit Kubernetes only throttles workloads, while reaching the memory limit evicts them from the node, which may cause a tsunami of eviction.
ResourceQuota keeps teams from not starving out each other. It allows you to set a limit on the aggregate resource consumption of a namespace. If you organize team workloads into distinct namespaces, you can keep them from harming each other, even attribute infrastructure cost to teams.
You can set up quotas on requests, limits, storage, loadbalancers, gpus, etc [3].
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: marketing
spec:
hard:
requests.cpu: '10'
requests.memory: 20Gi
limits.cpu: '20'
limits.memory: 40Gi
requests.nvidia.com/gpu: 4
By setting LimitRanges and ResourceQuotas, you prevent obvious misconfigs and major disasters.
But you will still have toil.
Developers will come to you when their workloads are not scheduled, as LimitRanges have the tendency to fail silently. The deployment is scheduled, but pods are not created. Something that surprises devs, and admins alike, like the violation of maxLimitRequestRatio that is only visible in kubectl get events.
You will also have to act when quotas are filled, but node utilization is low - a sign of requests are not set properly.
Time to close the feedback loop, limit the toil
Setting resource requests is not straightforward. It requires developers to know their application's runtime characteristics, or giving them tools and knowledge, so they are able to measure it.
Even without tooling, you can get an instant look of resource consumption with kubectl top pods, and generate 500 requests on 50 threads with this Apache Bench one-liner:
ab -n 500 -c 50 -p body.json -T application/json -H 'Authorization: Bearer xxx' https://myservice
But this is often overlooked. Requests are either set too low - overloading the cluster, or too high - wasting money.
But developers want to be good citizens, and as a cluster administrator, you can highlight these inefficiencies and close the feedback loop. They will be grateful that you allowed them to fully own their application and fix the misconfiguration.
Sadly, there are no built-in tools to report on cluster usage, but there are a few approaches, with varying effort to involved:
- you can come up with a sophisticated kubectl command
- set up a Grafana dashboard showing the situation
- or use something like the Kubernetes Resource Report
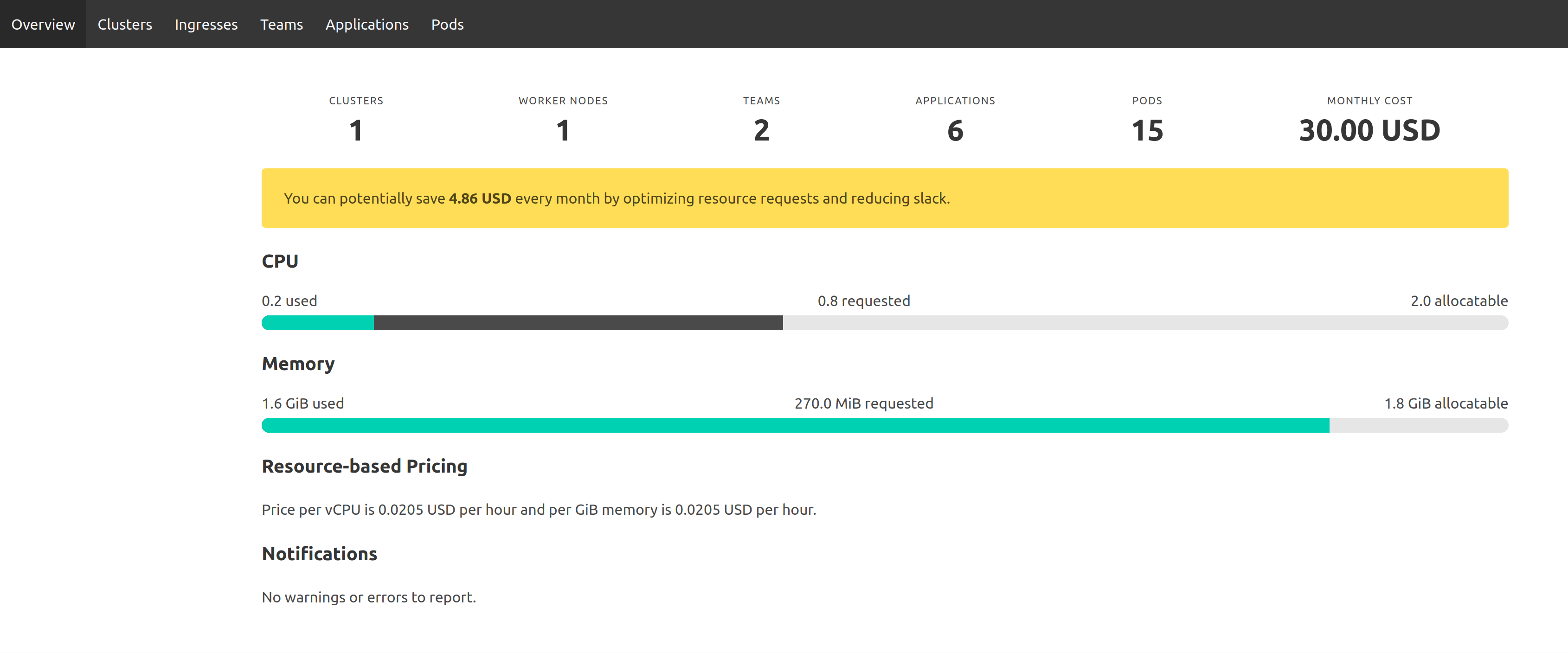
Even one manual report will mean a lot, and automated weekly Slack reports will get you the behavior you seek.
Bonus
The Vertical Pod Autpscaler project has a different approach.
It sets requests and limits based on actual utilization.
Vertical Pod Autoscaler (VPA) frees the users from necessity of setting up-to-date resource limits and requests for the containers in their pods. When configured, it will set the requests automatically based on usage and thus allow proper scheduling onto nodes so that appropriate resource amount is available for each pod. It will also maintain ratios between limits and requests that were specified in initial containers configuration.
It may worth checking out as it solves the cluster under/over utilization problem. However it is not widely adopted in the ecosystem at the time of writing, and the writer has no deep experience of using it.
Bonus 2
Developers want to be good citizens. If they have all the knowledge required to set requests and limits correctly, they would do it.
Trainings, wikis, enforcement, feedback loops all suffer from a key problem however. They are not helping when developers have the most attention on the problem. When they are setting requests and limits.
Often they are on a mission to deploy their application, and the configuration details are just obstacles to reach that goal. Setting just some value is often their approach to get through this hurdle.
In Gimlet, we build the knowledge right in the tooling. Developers have the hints right where they need it, when they focus on the problem.
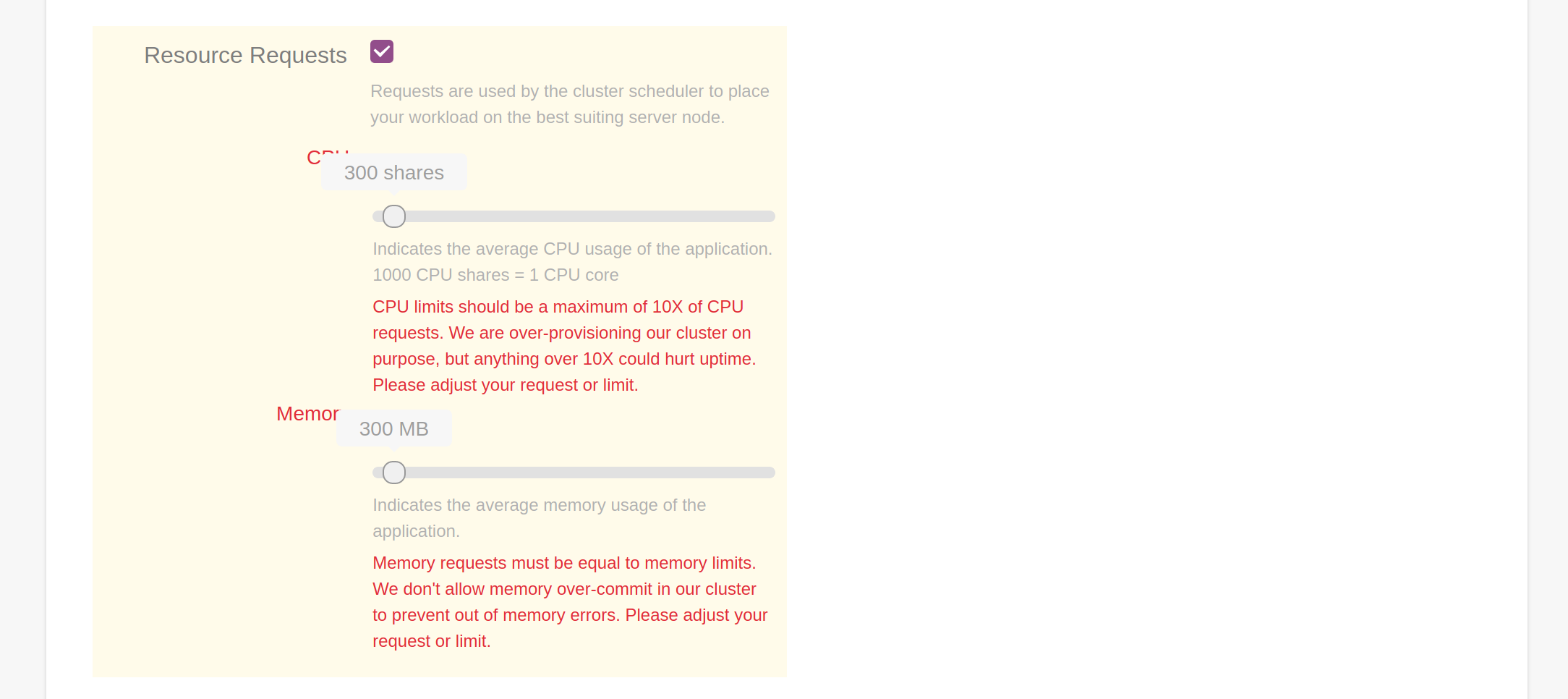
Gimlet helps developers on the first day, when they first deploy to Kubernetes, then keeps helping them on the second and third day with deployment and application operation. While following your company best practices.
We would be delighted if you check out Gimlet.
[1] https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
[2] https://sysdig.com/blog/kubernetes-limits-requests/
[3] https://kubernetes.io/docs/concepts/policy/resource-quotas/#enabling-resource-quota



